Claude Code ソースコード解説シリーズ 第5章: コンテキストガバナンス(選択)
コンテキスト管理を業界全体の視点から補足し、他の Agent システムと比較します。
『Claude Code ソースコード解析シリーズ』第5章|Context ガバナンス(オプション)
多くの人は Context Manage という言葉を初めて聞いたとき、次の二つのことだと理解します。
コンテキストウィンドウを大きくする。
履歴が埋まりそうになったら圧縮する。この理解は間違いではありませんが、視野が狭すぎます。
単なるチャットであれば、Context 管理はたしかに主にチャット履歴の処理です。しかしシステムがプログラミング Agent になると、特にファイルを読み取り、ツールを呼び出し、コマンドを実行し、コードを書き、外部システムを呼び出す Agent になると、Context はもはや単なる会話記録ではなく、モデルが各ターンで目にする現場全体になります。
本当の問題はこうなります。
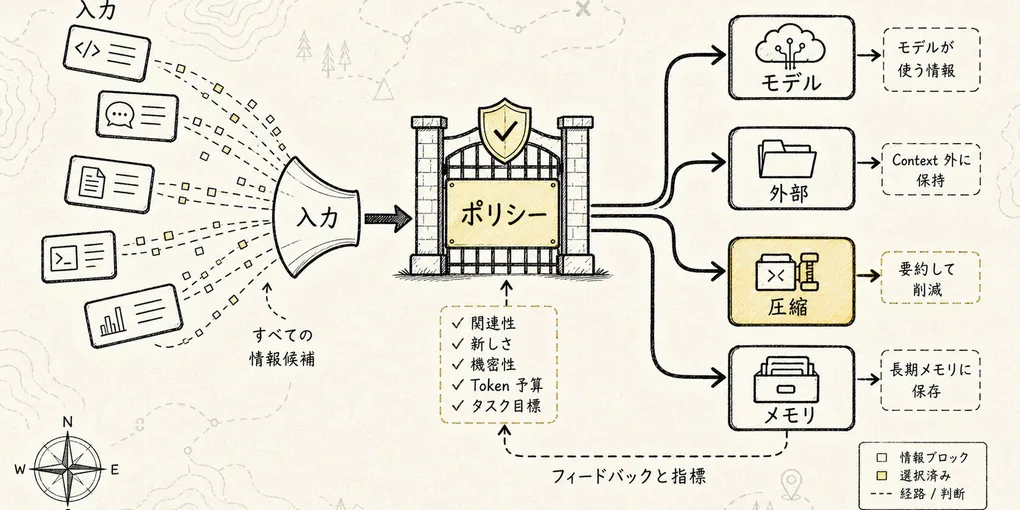
Agent はエンジニアリング実行の過程で、絶えず新しい情報を生み出していく。システムは、どの情報をモデルに入れ、どの情報を外部に留め、どの情報を圧縮し、どの情報を長期保存すべきかを、どうやって判断するのか?
この章はオプションなので、Claude Code だけの話にとどめません。
Claude Code は優れたサンプルです。プログラミング Agent が直面するコンテキスト問題を徹底的にさらけ出しているからです。ファイル内容は長く、ツールの結果は長く、テストログは長く、タスクも数十ターンに及ぶことがよくあります。しかし同じ問題は、LangGraph、OpenAI Agents SDK、AutoGen、Cursor、Devin、OpenClaw、Hermes といった異なる形態の Agent システムにも現れます。
ただ、プロジェクトごとに重点は異なります。
- Claude Code は長タスク CLI Agent(コマンドライン対話型 Agent)に近く、重点はツール結果、プロジェクトルール、圧縮と復元にあります。
- LangGraph はワークフローステートマシンに近く、重点は構造化された State、チェックポイント(実行スナップショット)、再開可能な実行にあります。
- OpenAI Agents SDK はアプリケーション開発 SDK に近く、重点はローカルランタイム context と LLM 可視 context の区別にあります。
- AutoGen はマルチ Agent 対話フレームワークに近く、重点はマルチロール協調、モデルコンテキスト、メモリ注入にあります。
- Cursor / Copilot は IDE 内のリアルタイムアシスタントに近く、重点は低レイテンシ、局所的なコード断片、検索にあります。
- Hermes / OpenClaw / Harness.io といったシステムは、より長期ランタイム、エントリ制御、エンタープライズガバナンスに寄っています。
つまり、Context Manage は特定のプロダクトに閉じた機能ではなく、あらゆる Agent エンジニアリングが直面する基盤レイヤーの問題です。前回は Claude Code 自身の圧縮パイプラインを取り上げましたが、今回は視点を広げて、その背後にある汎用的な統治モデルを見ていきます。
モデルはステートレスである。
タスクは連続している。
情報は爆発的に増える。
コンテキストウィンドウは有限である。
システムはターンごとに現場を再構成しなければならない。議論が浮遊しないよう、具体例に据えます。
ユーザー:このプロジェクト、ログイン後の遷移が失敗する。原因を特定して修正してほしい。実際に仕事ができる Agent なら、「ルートガードを確認してみてください」で済ませたりはしません。次のように動くはずです。
プロジェクト構造を把握する
-> ログイン関連のコードを検索する
-> ルートガードを読む
-> 認証の状態管理を読む
-> テストを実行する
-> エラーログを解析する
-> コードを修正する
-> 再度テストを実行する
-> 変更内容とリスクをまとめる各ステップで新しい情報が生まれます。Context Manage が解決すべきなのは、これらの情報を長大なタスクのなかで途切れさせず、かつモデルを情報過多で溺れさせないようにすることなのです。
1. なぜコンテキスト管理がエンジニアリング上の課題になるのか
まず最も基本的な事実を押さえておく:
モデル自体は、呼び出しのたびにステートレスである。
前のターンでどのファイルを読んだかを自然に覚えているわけでもなければ、さっきテストがどこで失敗したかを自然に知っているわけでもない。Agent が連続して作業しているように見えるのは、モデルの外側にあるランタイムが、ターンごとに「現在の作業現場」を組み立て直してモデルに送っているからだ。
通常のチャットにおける 1 ターンの呼び出しは、ざっくり次のように表せる:
ユーザーの質問
-> モデルの回答しかし Agent の 1 ターンの呼び出しは、むしろ次のような構造になる:
システムルール
+ プロジェクトルール
+ ユーザーの現在の目標
+ メッセージ履歴
+ ツール説明
+ 直近のツール実行結果
+ 現在のタスク状態
+ 圧縮された要約
+ 利用可能な外部リソース
-> モデルが次の一手を判断このとき、コンテキスト管理が答えなければならないのは「チャット履歴をどう保存するか」ではなく、次のような問いである:
- このターンでモデルは一体何を見るべきか?
- どの情報を毎ターン見せるべきか?
- どの情報は必要なときだけ取得すればよいか?
- どのツール実行結果がすでに古くなっているか?
- どのコンテンツが長すぎて、切り詰める必要があるか?
- どの履歴を要約に置き換えられるか?
- 圧縮後もタスクの連続性をどう保証するか?
- 複数 Agent 間でコンテキストをどう隔離するか?
- どの内部状態をモデルに露出させてはいけないか?
これはもはやシステム設計の問題であり、プロンプトの文案の問題ではない。
コンテキスト管理がなければ、Agent はすぐにいくつかの典型的な失敗に直面する。
1. トークン爆発
ツールの実行結果が積み重なり、モデルへのリクエストが際限なく長くなる。
一回の grep が数十件のマッチを返し、一回のテストが数千行のログを吐き出し、一つのソースファイルが数千トークンに及ぶこともある。長時間のタスクが後半に差しかかると、ウィンドウを本当に圧迫しているのはユーザーの発言ではなく、ツールが持ち帰った環境ノイズであることが多い。
(ここに落とし穴がある:多くの開発者は会話のターン数だけを見て「まだ 20 ターンだからウィンドウは十分あるはず」と考える。しかし実際には、毎ターンのツール呼び出しがコンテキストに内容を詰め込んでおり、20 ターン後にはトークンがすでに限界に達している可能性がある。)
2. コンテキスト汚染
古い情報がまだコンテキストに残っているが、現実はすでに変わっている。
たとえば Agent が先に auth.ts を読み、その後そのファイルを修正したにもかかわらず、履歴には古いバージョンの内容が保持されている。次のターンでモデルが古い内容に基づいて推論を続けると、非常に見えにくい問題が発生する:
一見、真剣に分析しているように見えるが、
分析対象はもはや現在のコードではない。3. 制約の消失
ユーザーが最初に「public API は変更しないで」と言っても、10 ターン目以降にはモデルが忘れている可能性がある。
プロジェクトルールで「マイグレーションファイルは手動で変更してはいけない」とあっても、コンテキストが圧縮された結果、そのルールがサマリーに含まれていないかもしれない。すると Agent は実行を続け、一見どのステップも合理的に見えるが、すでに境界を越えている。
4. 圧縮による記憶喪失
圧縮はフリーランチではない。
粗いサマリーは「どのファイルを読んだか、どのコードを変更したか」だけを記録し、以下のような情報を取りこぼすことがある。
- ユーザーの本来の目的
- 現在どの地点で詰まっているか
- これまでに試した手段
- 守るべき制約
- 次にやるべきこと
このような圧縮が行われたモデルは、会議の議事録だけを見た人のようなもので、だいたい何があったかは分かっていても、現場の手触りは失われている。
5. マルチ Agent による汚染
システムがサブ Agent やマルチ Agent の協調動作を導入すると、問題はさらに顕在化する。
検索 Agent が大量の資料を読み込み、実行 Agent は最終的な結論だけを必要とする。検索プロセスの草稿をすべて実行 Agent に渡してしまうと、下流の Agent は賢くなるどころか、ノイズに引きずられてしまう。
マルチ Agent システムで最も怖いのは、情報不足ではなく、各 Agent が他者の途中経過を背負ったまま走り続けることだ。
2. Context は Prompt でも Memory でもない
Context Manage の話に入る前に、まず混同しやすい用語を整理しておく。
| 概念 | 平易な説明 | 答えようとしている問い |
|---|---|---|
| Prompt | タスク指示 | モデルにどう要求すべきか? |
| Context | 現在の作業台 | モデルはこのターンで何を見ているのか? |
| Memory | 再利用可能な記憶 | どの事実をタスク横断で保持すべきか? |
| Transcript | 生の記録 | 全過程をどう監査・復元するか? |
| State | 構造化状態 | 現在のタスクの機械的状態は何か? |
| Artifact | 外部成果物 | ファイル、ログ、diff、レポートはどこにあるか? |
日常にたとえるなら:
Prompt は問題用紙の設問。
Context は机の上に広げた資料。
Memory は資料キャビネット。
Transcript は録音・録画データ。
State はプロジェクトのカンバンボード。
Artifact は実際に生成されたドキュメントやコード。多くの Agent が制御不能に陥るのは、これらがごちゃ混ぜになっているからだ。
Transcript を Context として扱うと、毎ターン token 爆発を起こす。
Context を Memory として扱うと、一時的なノイズが長期記憶を汚染する。
Memory を Prompt として扱うと、モデルは「経験」を逸脱不可能な強制ルールと誤読する。
State を自然言語の履歴のなかにだけ置くと、長いタスクで圧縮がかかった瞬間に消失する。
だから Context Manage の第一原則はこうだ:
すべての情報を一本のチャット履歴に詰め込まないこと。
工学的により堅牢なやり方は、異なる情報を異なるレイヤーに置き、毎ターンのモデル呼び出しの直前に、そのターンに必要なごく一部だけを動的に組み立てることだ。
3. まずは動作レイヤーとアーキテクチャレイヤーを区別する
Context Management を解説する資料の多くは、まず次のような一連の動作を列挙します。
Offload:大きなオブジェクトをプロンプトから追い出す
Reduce:切り詰め・抽出・要約
Retrieve:必要なときに呼び戻す
Isolate:タスクを独立したコンテキストに分割する
Cache:安定したコンテキストや計算結果を再利用するこの五つの動作は有用です。しかし、これらが答えているのは次の問いです。
コンテキストが多すぎるとき、どんな処理ができるか?一方、エンジニアリングとしての実装では、さらに手前にある問いに答えなければなりません。
この情報はモデルに見せていいものか?
どちらがより信頼できる情報源か?
いまこれはホット情報か、コールド情報か?
原文で渡すべきか、要約・引用・構造化された状態で渡すべきか?
どこから呼び戻すのか?
真実を落とさずに圧縮するにはどうすればいいか?
どの境界の中で使うのか?だからこそ、ローカルの wiki にある「Agent コンテキスト管理:七次元モデルとコンテキスト OS」のほうが価値を持つのです。この資料は Context Management を「処理動作のチェックリスト」から「七次元のアーキテクチャモデル」へと引き上げています。
動作レイヤーは工具箱、七次元モデルは設計図です。
工具箱はハンマー・ペンチ・ドライバーの存在を教えてくれます。設計図は、どこを叩いていいのか・どこを叩いてはいけないのか、どの層から組み立てるのか、問題が起きたときにどの責務を追うのかを教えてくれるのです。
4. 七次元モデル:コンテキストを統治可能なワーキングセットにする
Context Manager を一つのサブシステムとして捉えるなら、最低でも七つの次元で情報を管理する必要がある。
Visibility:モデルから見える情報は何か
Authority:競合時にどちらが優先されるか
Temperature:情報がホット・ウォーム・コールド・フリーズ・長期記憶のどの層にあるか
Shape:情報がどのような形態で存在するか
Retrieval:情報が不足しているとき、どこから取得するか
Compression:長すぎるとき、真実を失わずにどう圧縮するか
Boundary:異なるタスク・Agent・テナント・権限の間でどう隔離するかこの七次元はただの並列概念ではない。非常に実践的なエンジニアリングパイプラインを成している。
1. Visibility:まずモデルに見せるべきかどうかを決める
最初の関門は圧縮ではなく、可視性である。
コンテキストは大きく三つに分類できる。
| 種類 | 例 | 扱い方 |
|---|---|---|
llm_visible | ユーザーの目標、プロジェクトルール、重要なコードスニペット、フィルタ済み検索結果 | モデルのコンテキストに投入してよい |
runtime_only | APIキー、権限オブジェクト、セッション、トレース、内部依存、DB接続 | ツールとランタイムのみが使用 |
artifact_ref | 大きなログ、大きなファイル、Webページスナップショット、完全なdiff | 実体は外部に置き、モデルには参照とプレビューのみ |
多くの Agent システムが初期に犯しがちな間違いは「ツールが取得できる → モデルにも見せるべき」と思い込むことだ。
たとえば OpenAI Agents SDK は、local context と LLM context を明確に区別している。要するに Visibility の話だ。ツール関数は現在のユーザーオブジェクトやロガー、DIコンテナ、権限情報を必要とするかもしれないが、モデルはそれらを見る必要はなく、ましてや secret(APIキーなどの機密設定)を見せるべきではない。
一言で覚えるなら:
モデルに見せなくていいものは見せない。参照で表現できるものは、原文を貼らない。
2. Authority:競合には必ず裁定チェーンを設ける
コンテキストではしばしば競合が発生する。
ユーザーが今「generated ファイルを直接書き換えて」と言う一方、プロジェクトルールには「生成ファイルを変更するな」と書いてある。長期記憶は「ユーザーは Redis を好む」と言い、現在のタスクは「Redis を持ち込むな」と言う。古い要約はテストが通ったと言い、最新のツール実行結果はテスト失敗を示している。
システムに明示的な裁定チェーンがなければ、それは衝突をモデルの語感任せで判断させるのと同じことだ。
無難なデフォルトの優先順位としては、次のようなものが考えられる。
System / Safety Policy
> Tenant / Organization Policy
> Project Rules
> Current User Instruction
> Current Task State
> Verified Retrieval Result
> Long-term Memory
> Historical Summary
> Raw Old Conversationこのチェーンの意図は「すべてのシステムがこう並べるべき」ではなく、次を意識させることにある。
Authority は設計されるべきものであり、プロンプトに「遵守してください」と何行か書き足して済むものではない。
Claude Code のシステムルール、プロジェクトルール、パーミッションモード、ツールの安全検査は、つまるところ複数のレイヤで Authority を協調実装しているにすぎない。エンタープライズ向け Agent における RBAC(ロールベースアクセス制御)、approval(承認フロー)、audit(監査)は、Authority をプロンプトからランタイム、そして組織ガバナンスへと引き上げるものだ。
3. Temperature:情報は冷熱のレイヤで分ける
コンテキストは「短期」と「長期」の二層にとどまらない。
より使い勝手の良い分け方は次のとおりだ。
| レイヤ | 意味 | 例 |
|---|---|---|
| Hot | 現在必須、デフォルトでプロンプトに入る | 現在のユーザー目標、直近の失敗ログ、編集中のファイル |
| Warm | 現在関連する可能性があり、通常は要約または状態化して保存 | 除外済みの原因、読了ファイルの概要、現在の仮説 |
| Cold | 必要時に呼び出す | コードインデックス、ドキュメントインデックス、過去セッション |
| Frozen | 完全な元記録、監査と復元のみに使用 | トランスクリプト、完全ログ、Webページのスナップショット |
| Long-term Memory | セッションをまたぐ安定した事実 | ユーザーの安定した好み、プロジェクトの慣例、長期ルール |
これにより Context Manager は、よりメモリマネージャらしく振る舞う。
Hot は使い終わったら Warm に降格する。
Warm は安定したら Long-term Memory に入ることがある。
Cold は検索でヒットしたら Hot に昇温する。
Frozen はプロンプトに入らないが、真実を復元できる。
これは圧縮サマリが陥りやすい問題でもある。多くのシステムは Hot な現場を Warm なサマリに圧縮する一方で、直近の末尾を保持しない。その結果、モデルは次のターンで現場感覚を失ってしまう。
### 4. Shape:同じ情報に異なる表現形態を持たせる
すべての情報を自然言語で書こうとしてはならない。
たとえば同じ失敗ログであっても、複数の形態がありうる:
| 形態 | 適した場面 |
| --- | --- |
| Raw | 生の内容を一行ずつ分析したいとき |
| Extract | コマンド、終了コード、エラー種別、主要スタックだけ欲しいとき |
| Summary | 古い履歴を振り返るとき |
| Structured State | 現在のタスク状態、失敗試行、次の一手 |
| Reference | 原文が長すぎるため artifact ID やパスだけ残すとき |
| Diff | ファイル全体よりコード変更が重要なとき |
| Graph | モジュール関係、タスク DAG、テーブルリレーション |
たとえばテスト失敗ログは、そのままモデルに渡すのではなく、次のように変換できる:
```yaml
command: pnpm test auth
status: failed
error: TypeError user.id should be string
file: src/auth/session.ts
test: redirects after login
artifact: logs/test-auth-2026-05-03.txt
next_step: inspect mock user constructionこれが Shape の価値だ:
同じ情報でも表現形態を変えれば、トークンコスト・検索性・信頼性がすべて変わる。
LangGraph の State、Claude Code の compact summary、OpenAI Agents SDK の tool context、企業向けパイプラインの execution context は、いずれもこの Shape という軸から理解できる。
5. Retrieval:リトリーバルはベクトル検索だけではない
リトリーバルといえばベクトル DB、と思われがちだが、Agent における検索経路はそれだけにとどまらない。
成熟したシステムであれば、少なくとも次のようなマルチパス検索を備えている:
| 検索経路 | 適した場面 |
|---|---|
| Recent Tail | 直近の会話、現在のツール結果、現在の状態 |
| Rule Loading | AGENTS.md、CLAUDE.md、プロジェクトルール |
| Keyword Search | 関数名、エラーコード、フィールド名、設定項目 |
| Vector / Hybrid Search | ドキュメントの意味、類似経験、複雑な知識 |
| Tool Search | ツール・スキル・プラグインの段階的ロード |
| Artifact Lookup | 巨大ログ、巨大ファイル、Web 取得結果 |
| Memory Search | ユーザー設定、長期的な事実、プロジェクトの慣習 |
| Graph Traversal | モジュール依存、タスク DAG、データベースリレーション |
コードの世界では、キーワード、シンボル、ファイルパスが純粋なベクトルよりも重要なことが多い。
エンタープライズナレッジベースでは、ハイブリッド検索、権限フィルタリング、ソースの信頼性のほうが重要だ。
マルチエージェントの世界では、アーティファクトのルックアップと構造化されたハンドオフのほうが重要だ。
つまり、Retrieval の本質は「RAG があるかどうか」ではない。
この種のタスクで情報が不足したとき、最も信頼できる情報の入り口は何か?
6. Compression —— ワーキングセットを絞り込むことであって、真実を消すことではない
圧縮もまた、LLM による要約だけではない。
以下のように分類できる。
| 圧縮方法 | 意味 | リスク |
|---|---|---|
| Truncate | そのまま切り捨て | 重要な制約を落としやすい |
| Extract | キーフィールドを抽出 | 抽出ルールが不完全だと情報が漏れる |
| Summarize | モデルで要約 | 要約ドリフトが起きやすい |
| Distill | 構造化状態へ帰納 | スキーマ設計が必要 |
| Archive + Ref | 原文は外部保存し、参照のみ残す | 後でリハイドレートできる必要がある |
| Rehydrate | 必要時に原文を再展開 | 追跡可能な出典を保持する必要がある |
より安全な順序は通常、次のとおりだ。
まず大きなオブジェクトを Offload
→ キーフィールドを Extract
→ 構造化状態へ Distill
→ 古い履歴を Summarize
→ どうしても必要なときだけ Truncate圧縮の最大のリスクは要約ドリフトだ。要約がいつの間にか、ユーザーの制約、失敗原因、未解決の問題を書き換えてしまう。
そのため、圧縮結果には必ず以下を残さなければならない。
- ソース範囲
- 重要な制約
- 失敗した試行
- 未解決の問題
- アーティファクト参照
- 次の一手
これは Claude Code 式の compact の核心と一致する。要約は読書感想文ではなく、引き継ぎ書を書くことなのだ。
7. Boundary —— 隔離はメインスレッドの自衛手段である
Boundary は最も過小評価されがちな次元だ。
サブエージェントの価値は「並列で作業すること」だけではない。コンテキストの隔離にある。
以下のタスクは特に隔離に適している。
- 大規模な検索と資料調査
- 長大なログ分析とテストのトラブルシューティング
- コードベースのスキャンと Web スクレイピング
- データクレンジングと独立したサブタスクの実装
- 高い権限を要するツール呼び出し
- マルチテナントのデータアクセス
境界には多くの層があり得る:
| 境界 | 役割 |
|---|---|
| Thread | 異なる会話コンテキストの分離 |
| Task | 異なるタスク状態の分離 |
| Subagent | サブタスクの局所コンテキスト分離 |
| Tool | ツールの権限および入出力の境界 |
| Artifact | 大規模オブジェクトを外部化し、メッセージストリームを汚染しない |
| Permission | 高リスク操作の承認 |
| Tenant | 異なる組織・ユーザー・データドメインの分離 |
| Sandbox | 実行環境の分離 |
優れたサブエージェント設計は次のようになるべきだ:
入力は狭く:タスク + 制約 + アーティファクト参照
出力は狭く:結論 + 根拠 + 推奨される次のステップ + 信頼度メインスレッドは、サブスレッドの全過程の再現を受け取るべきではない。
境界(Boundary)のないマルチエージェントは、いとも簡単に「協調」から「相互汚染」へと転落する。
5. エージェントがタスクを実行するとき、コンテキストはどう膨らんでいくのか
ログイン後リダイレクトのバグ事例に戻ろう。
最初にユーザーが与えたのはたった一言だ。
このプロジェクト、ログイン後のリダイレクトが失敗する。原因を探して直してほしい。エージェントが実際に問題を解決しようとすれば、次のようなコンテキストが生成されていく。
| ステップ | 新たに生まれる情報 |
|---|---|
| ディレクトリを見る | プロジェクト構造、フレームワーク種別、エントリポイント |
| package.json を読む | テストコマンド、依存関係、スクリプト |
| login を検索する | 該当ファイル、関連関数、ルートパス |
| ルートガードを読む | 認証ロジック、redirect の処理 |
| 状態管理を読む | token、user、session の保存方式 |
| テストを走らせる | 失敗ログ、スタックトレース、テスト名 |
| コードを修正する | diff、変更ファイル、実装仮説 |
| 再度テストを走らせる | 新しい結果、新しいエラー、または通過の証明 |
これらの情報には「熱い」ものもあれば、すぐに「冷める」ものもある。
現在の失敗ログは熱い。次のステップで原因を絞り込む手がかりになるからだ。
過去の検索結果はぬるい。まだ参考になる可能性はあるが、必ずしもそのまま残す必要はない。
最初に読んだ古いファイル内容は、ファイルが変更された時点で冷める。むしろノイズ源にさえなりうる。
完全なトランスクリプトは重要だが、それはコールドアーカイブであり、毎ターンまるごとモデルに詰め込むべきではない。
だから Context Manager に求められるのは「全部保存する」ことではなく、絶えず次の判断を下すことだ。
いまこの一手で、モデルが最も見るべき情報はどれか?これがコンテキストガバナンスの核心である。
6. エンジニアリングで遭遇する問題とその対処法
ここでは、Context Manage におけるエンジニアリング上の問題を「症状 → 根本原因 → 解決策」に分解して説明する。
問題 1:モデルが現場を把握していない
症状:エージェントが推測で動き始める。
ルーティングコードを読んでいないのに遷移ロジックを変更しようとしたり、テストを見ていないのに「トークンが保存されていないのが原因だろう」と言い出したり、プロジェクトのルールを確認せずに自分の慣れたディレクトリ構成に変えようとしたりする。
根本原因:モデルの推論能力の問題ではなく、現在のコンテキストに十分な現場情報がないこと。
解決策:動的なコンテキスト注入。
- 起動時にプロジェクトルールと作業ディレクトリ情報を読み込む。
- 現在のタスクに関連するファイルを必要に応じて読み取る。
- 検索結果はまず候補として扱い、一度にすべてを詰め込まない。
- ツールの実行結果はメッセージ履歴または構造化された状態に書き戻す。
- 外部知識が必要な場合は、検索、Web、MCP、データベースツールを通じて取得する。
ここでのポイントは「オンデマンド」であること。
コンテキストは多ければ多いほど良いわけではない。安定したエージェントとは、最も多くの資料を読んだエージェントではなく、各ターンで最も関連性の高い資料を取得できるエージェントである。
問題 2:ツールの出力が長すぎる
症状:トークン消費量が急増し、モデルの応答が徐々に遅くなり、最終的にコンテキスト制限に達する。
根本原因:多くの場合、ユーザーとの会話が長すぎるのではなく、ツールの出力が肥大化していること。
解決策:まずツールの出力を制御し、その後に会話履歴を制御する。
- ツールの種類ごとに出力バジェットを設定する。
- 長大なログはエラーサマリ、重要なスタックトレース、終了コード、関連ファイルのみを残す。
- 大きなファイルは断片、行番号、シンボルインデックス、または参照を優先して返す。
- 検索結果はまずマッチの概要を返し、モデルが必要としたときに具体的なファイルを読み取る。
- 古くなったツール出力はスニップ(snip)またはマイクロ圧縮(micro compact)を行う。
これは Claude Code に非常に典型的な問題だ。プログラミングエージェントにおいて、ウィンドウを最も圧迫しやすいのは推論ではなく、Bash、Read、Grep といったツールが実世界の情報を返しすぎることにある。
(実際の本番環境で、find . -name "*.log" が 12MB の内容を返し、それがそのままコンテキストに流れ込んだ惨事を目にしたことがある。その後、単一ツールの出力が 4KB を超えたら自動的にアーティファクト化するハードリミットを導入した。)
問題 3:古い情報が新しい判断を汚染する
症状:エージェントが古いコードに基づいて分析を続けたり、すでに排除した方向性を繰り返し調査したりする。
根本原因:コンテキストに「情報の鮮度」が欠けていること。
解決策:コンテキストにライフサイクルを与える。
- ファイル読み取り結果にはバージョン、mtime、ハッシュ、または読み取り時刻を記録する。
- ファイルが変更されたら、古い読み取り結果は重みを下げるか、期限切れとしてマークする。
- テストログは対応するコミット、コマンド、時刻と紐付ける。
- 検索結果はあくまで手がかりとして扱い、現在の事実としては扱わない。
- 重要な事実は自然言語の要約だけでなく、可能な限り出典を引用する。
これこそが、Context Manager を単なる文字列連結ツールにしてはいけない理由です。情報をテキストの塊としてではなく、メタデータ付きのオブジェクトとして扱うべきなのです。
問題4:ルール間の競合
症状:システムルール、プロジェクトルール、ユーザーの現在の指示、長期記憶が互いに矛盾する。
例:
システム要件:シークレットを漏洩してはならない。
プロジェクトルール:生成ファイルを変更してはならない。
ユーザーの現在の指示:generated ファイルを直接修正してほしい。
長期記憶:ユーザーは素早い完了を好む。これらがすべて自然言語のままコンテキストに詰め込まれていると、モデルは言語感覚だけでどれかを選んでしまう可能性があります。
解決策は、権威の階層を明確にすることです:
システム / セキュリティポリシー
-> 組織レベルのルール
-> プロジェクトレベルのルール
-> 現在のユーザー指示
-> 長期プリファレンス
-> 検索結果とツール結果実装上は、ルールを次のように分類できます:
- 強制制約:システムが必ずインターセプトまたは承認を求める。
- ソフト制約:コンテキストに注入し、モデルの判断に委ねる。
- 状況制約:対象パス、ツール、タスクにマッチした場合のみ注入する。
巨大なプロジェクトで、1つの超長大な AGENTS.md や CLAUDE.md が必ずしも良いとは限らない理由もここにあります。ルールが長すぎ、広すぎ、矛盾しすぎると、最終的にコンテキストノイズになります。
(実戦経験:ルールファイルが500行を超えると、モデルはむしろその中の制約を無視し始めます。複数ファイルに分割し、必要に応じて読み込む方が効果的です。)
問題5:圧縮後のタスク断線
症状:compact 実行後、モデルは「何が起きたか」の概要は把握しているが、「次に何をすべきか」がわからない。
根本原因は、要約が「履歴」だけを記録し、「状態」を記録していないことです。
優れた圧縮要約とは、文章のまとめではなく、タスク引き継ぎ書です。
最低限、以下を保持すべきです:
ユーザーの目標
破ってはならない制約
現在のフェーズ
既読の重要ファイル
変更済みファイル
重要な判断とその根拠
失敗した試行
直近のテスト結果
推奨される次の一手また、圧縮後は直近数ラウンドの生メッセージと重要なツール実行結果を残すのが望ましいです。
次のように捉えるとわかりやすいでしょう:
要約は「本筋」を保持する役割。
直近の末尾は「現場感覚」を保持する役割。これは「古い履歴をすべて1段落に押し込む」よりも、はるかに安定したアプローチです。
問題6:マルチエージェントの相互汚染
症状:サブエージェントの下書き、仮説、失敗経路が別のエージェントに影響を与える。
根本原因は、すべてのエージェントが1つの線形チャット履歴を共有していることです。
解決策はコンテキストの分離です:
- 子 Agent は局所的なタスクを受け取り、グローバルな履歴は受け取らない。
- 子 Agent は構造化された結果を返し、完全な思考過程は返さない。
- 上流は検証可能な成果物、参照、結論のみを渡す。
- 共有状態はスキーマで管理し、自然言語による言い換えでやり取りしない。
- 各 Agent は独自のツール権限とコンテキスト予算を持つ。
複雑なタスクにおいては、コラボレーションよりも隔離の方が重要であることが多い。
隔離のないマルチ Agent は、「複数人での協業」から「複数人で同じ机を同時に汚す」状態へと容易に転落する。
問題七:コストとレイテンシの制御不能
症状:Agent は動くが、すべてのステップが遅く、高コストで、冗長である。
根本原因は、毎ターンに固定コンテンツを過剰に詰め込んでいるか、毎回再検索・再読み込み・再解釈を行っていることにある。
解決策:
- prompt cache:安定したシステムプロンプトとツール説明は可能な限りキャッシュする。
- lazy loading:ツールの詳細説明、ルールファイル、長文ドキュメントはオンデマンドで読み込む。
- progressive disclosure:最初に要約と索引を提示し、必要に応じて全文を展開する。
- local context:ランタイムの依存関係や内部状態はモデルに送らない。
- structured state:機械可読な状態を自然言語トークンに変換しない。
ここで最も重要な判断は以下である:
大規模なコンテキストウィンドウは容量の問題を解決するが、情報規律の問題は解決しない。
ウィンドウがどれほど大きくても、毎ターン無関係な情報を大量に詰め込めば、モデルは依然として遅く、高コストで、容易に脱線する。
7. さまざまなプロジェクトにおけるコンテキストの扱い方
ここからは、代表的なプロジェクトをいくつか同じ図に並べて見ていく。
優劣をつけるためではなく、「ホスト環境によって、コンテキスト管理の重点がまったく異なる」ということを明確にするためだ。
1. Claude Code:長時間実行 CLI Agent におけるコンテキスト防御線
Claude Code の典型的なユースケースは次のようなものだ。
実際のコードリポジトリ上で、ファイルの読み込み、コード修正、コマンド実行、バグ修正を連続的に行う。ここで最も顕在化するコンテキスト上の問題は、ツール実行結果と長時間タスクの履歴である。
そのため、Claude Code のコンテキスト管理の重点は以下の点に置かれている。
- プロジェクトルール:
CLAUDE.md、ルールファイル、パススコープなどを通じてプロジェクトコンテキストを注入する。 - ツール結果のガバナンス:巨大なファイル、長大なログ、大量の検索結果を無制限にメッセージ履歴へ流し込まない。
- 自動圧縮:コンテキスト上限が近づいた時点で、履歴を要約に折りたたみ、処理を継続する。
- セッション復帰:transcript、resume、直近の末尾履歴によって、タスクの断線を防ぐ。
- サブ Agent による隔離:検索、分析、実装などのタスクを分離し、メインコンテキストへの負荷を下げる。
Claude Code から得られる示唆は次のとおりだ。
プログラミング Agent のコンテキスト管理において、最優先事項は「長期記憶」ではなく、「ツールループを途切れさせず走らせ続けること」である。
なぜなら、Claude Code が実際に直面しているのは以下のようなものだからだ。
ファイルが長すぎる。
ログが長すぎる。
エラーが多すぎる。
タスクのターン数が多すぎる。
ユーザー制約を失ってはならない。つまり Claude Code は、「メインループに組み込まれたコンテキストガバナンスの防御線」に近いものだと言える。
2. LangGraph:チャット履歴から構造化された State へのコンテキスト分離
LangGraph の視点はやや異なる。
Agent を単一のチャット履歴としてではなく、グラフとして捉える。
ノード実行
-> State 更新
-> チェックポイント
-> 次のノードへ継続そのコンテキスト管理の重点は以下のとおりだ。
- State スキーマ:どの情報がタスク状態なのかを定義し、構造化して保存する。
- チェックポイント:各 super-step の後にグラフの状態を保存する。
- スレッド:同一セッションまたはタスクにおける状態の系列。
- タイムトラベル:過去のチェックポイントに遡り、デバッグや分岐を行える。
- フォールトトレランス:ノード障害時に、成功したチェックポイントから復旧する。
これが示唆するのは次のことだ:
チャット履歴にすべての状態管理を任せてはいけない。
明確なステップ、明確なマイルストーン、明確な中間状態を持つタスクであれば、自然言語の対話に詰め込むより、LangGraph のような状態グラフに落とし込んだほうがはるかに安定する。
Claude Code は「長時間タスクの対話的実行」に近く、LangGraph は「再開可能なワークフロー状態マシン」に近い。
どちらもコンテキスト管理を扱っているが、切り口が異なる:
Claude Code:まずメッセージとツール実行結果を整える。
LangGraph:まず状態と実行境界を整える。3. OpenAI Agents SDK:ローカルコンテキストと LLM コンテキストを分離する
OpenAI Agents SDK のドキュメントには、非常に重要な区別が示されている:
ローカルコンテキスト:自分のコードやツールの実行時に見えるコンテキスト。
LLM コンテキスト:モデルが生成時に実際に見ることができるコンテキスト。この区別はきわめて工学的だ。
多くの開発者はコンテキストを「モデルに送るもの」と捉えがちだ。しかし実際のアプリケーションでは、ツールが必要とするがモデルには見せる必要のない情報や、モデルに見せるべきでない情報さえ存在する。
たとえば:
- データベース接続
- ロガー
- 現在のユーザーオブジェクト
- 権限状態
- 内部依存
- ツール呼び出しのメタデータ
- 使用量統計
これらはローカルの RunContextWrapper のようなオブジェクトに格納し、ツール関数やライフサイクルフックから利用するのが適切であり、モデルのコンテキストに直接注入すべきではない。
モデルが知る必要のある情報は、以下のようないくつかの経路で LLM コンテキストに入れることができる:
- インストラクションに含める。
- そのターンのインプットに含める。
- ツールとして公開し、モデルが必要に応じて呼び出せるようにする。
- 検索(retrieval)やウェブ検索でオンデマンドに補完する。
OpenAI Agents SDK が示唆するのは次のことだ:
コンテキスト管理の第一歩は、「ランタイムに必要なもの」か「モデルに必要なもの」かを区別することだ。
これにより、次の二つの悪い結果を回避できる:
モデルに見せるべきでない内部状態をプロンプトにリークさせてしまうこと。
モデルが不要な依存オブジェクトをトークンとして浪費してしまうこと。4. AutoGen:マルチエージェント環境におけるモデルコンテキストと記憶の注入
AutoGen の典型的なシナリオは、マルチエージェントによる対話と協調である。
こうしたシステムにおける問題は、「あるエージェントが忘れるかどうか」ではない。「複数のエージェントがどのように情報を共有し、ロールを分離し、メッセージ履歴を制御するか」である。
AutoGen におけるコンテキスト管理の重点は以下のとおりだ。
- モデルコンテキスト:各エージェントがモデルを呼び出す際に、どのメッセージを参照できるか。
- メモリ:メモリストアから関連コンテンツを検索し、モデルコンテキストを更新する。
- ロール分離:エージェントごとに責務と可視情報が異なる。
- チームオーケストレーション:複数エージェント間のメッセージ受け渡しと終了条件。
- コンテキストバリアント:シナリオによっては完全な履歴を保持し、別のシナリオではウィンドウまたは先頭と末尾のみを保持する。
AutoGen から得られる示唆は次のとおりだ。
マルチエージェントシステムにおいて、コンテキスト管理とはまず境界管理である。
レビュアーエージェントに、実行者が持つすべてのツール権限を渡してはならない。
リサーチャーエージェントに、検索時の下書きすべてをライターへ詰め込ませてはならない。
プランナーエージェントの中間仮説が、自動的に全体のファクトになってはならない。
マルチエージェントとは、より多くのモデルを同じチャットボックスに放り込むことではない。ロールごとに異なるコンテキスト、異なる状態、異なる出力契約を割り当てることである。
5. Cursor / Copilot:IDE シナリオでは低レイテンシと局所的な関連性を優先する
IDE アシスタントのシナリオはまた事情が異なる。
これらは多くの場合、コードを書いている最中に高速な補完、説明、書き換えを行う必要がある。ここでの中心的な対立軸は「長時間タスクの復帰」ではない。
極めて短い時間で、現在のカーソル付近にとって最も有用なコードコンテキストを見つけること。そのため、IDE シナリオにおけるコンテキスト管理は、より次の方向に偏る。
- カーソル前後のコード断片
- 現在のファイルのシンボル
- import および型情報
- 類似コードブロック
- 最近編集したファイル
- セマンティックインデックスまたは増分インデックス
必ずしも毎回、プロジェクト全体の理解が必要なわけではない。
多くの場合、低レイテンシの局所的なヒューリスティクスのほうが、重量級のグローバル検索よりも実用的である。
ここから得られる示唆は次のとおりだ。
コンテキスト管理はシナリオに奉仕すべきであり、デフォルトで最も完全なものを追求してはならない。
補完タスクには速さ、近さ、正確さが求められる。
バグ修正タスクには長い呼び出し連鎖、ツールのフィードバック、復帰が必要になる。
エンタープライズのワークフロータスクには権限、監査、プロセスコンテキストが必要になる。
場面によって「良いコンテキスト」はまったく異なる。
6. Hermes / OpenClaw / Harness.io:長時間ランタイムとガバナンスのコンテキスト
さらにもう一段上に行くと、Context Manage は単一タスクの管理から、ランタイム全体のガバナンスへとスコープが広がる。
OpenClaw は、パーソナル Agent のエントリポイント兼コントロールプレーンに近い。マルチチャネルメッセージ、自動化タスク、デバイスノード、ブラウザ、ローカル機能を、同一のセッションシステムにどう接続するかが焦点になる。
Hermes は、自己改善型の Agent ランタイムに近い。長期記憶、ユーザープロファイル、スキルの蓄積、セッションをまたぐ検索、再利用可能な経験が焦点になる。
Harness.io のようなエンタープライズワークフローシステムでは、パイプラインコンテキスト、シークレット、コネクター、RBAC、承認フロー、監査といった観点がより重要になる。
これらに共通するのは:
コンテキストがもはや単なるモデル入力ではなく、実行環境全体の一部になっている という点だ。
このレイヤーまで来ると、Context Manage が扱うべき対象はさらに増える:
- 誰がタスクをトリガーしたか。
- そのタスクがどのチャネルから来たか。
- 現在の実行環境が誰のマシン/サンドボックスか。
- どのシークレットが利用可能か。
- どの承認が通過済みか。
- どの過去の経験が再利用できるか。
- どの操作が監査対象として必須か。
つまり、Context Manage の終着点は「より賢いプロンプト」ではなく、Agent Harness の一部 だということだ。
8. 並べて比較する
これらのプロジェクトを同じ座標軸に並べてみよう。
| プロジェクト / システム | 主なシーン | Context Manage の核心 | 解決する主な課題 | 見落としがちな境界 |
|---|---|---|---|---|
| Claude Code | CLI プログラミングAgent | プロジェクトルール、ツール結果、圧縮、復元 | 長時間タスクの継続性、ツール出力のウィンドウ溢れ防止 | 圧縮サマリによって現場の詳細が失われる可能性 |
| LangGraph | グラフ型ワークフローAgent | State、checkpoint、thread、time travel | 状態の復元可能性、ノードのデバッグ容易性 | モデル入力は依然として別途管理が必要 |
| OpenAI Agents SDK | アプリ型Agent SDK | local context と LLM context の分離 | ツール依存、ランタイム状態、モデル可視情報のレイヤ化 | どの情報をモデルに注入するかは依然として開発者の設計判断 |
| AutoGen | マルチAgent 協調 | model context、memory、役割境界 | マルチロールのメッセージ伝達と記憶強化 | 共有履歴が多すぎると相互汚染が発生 |
| Cursor / Copilot | IDE リアルタイムアシスタント | カーソル近傍、類似コード、インデックス検索 | 低レイテンシでの局所的関連コンテキスト取得 | 長時間タスクの状態管理にはデフォルトでは不向き |
| Hermes / OpenClaw | 個人向け常駐型ランタイム | gateway、memory、skills、session search | マルチエントリ、長期記憶、経験の再利用 | 長期記憶の陳腐化と汚染を防ぐ必要がある |
| Harness.io 系システム | エンタープライズフローAgent | pipeline context、secrets、RBAC、audit | Agent をガバナンス可能なフローに組み込む | フロー境界によって柔軟性が制約される |
この表が最も伝えたいのは次の点だ。
各プロジェクトは同じ問題に異なる答えを出しているのではなく、異なるホスト環境で異なるコンテキスト圧力に対処しているのである。
Claude Code の圧力は長時間タスクとツール出力に起因する。
LangGraph の圧力は状態の復元可能性に起因する。
OpenAI Agents SDK の圧力はアプリケーションランタイムとモデル入力の境界に起因する。
AutoGen のプレッシャーはマルチエージェント協調に由来する。
Cursor のプレッシャーは低レイテンシが求められるコード編集シナリオに由来する。
Hermes / OpenClaw のプレッシャーは長時間実行とマルチエントリポイントに由来する。
エンタープライズ向け harness のプレッシャーは権限管理、監査、プロセスへの埋め込みに由来する。
9. ミニマルな Context Manager を自作する場合
Mini Agent を自作する場合、いきなり複雑なベクトルデータベースや多層記憶機構に手を出すのはおすすめしない。
より堅実なアプローチは、Context Manager を以下のようないくつかの小さなコンポーネントに明確に分割することだ。
| コンポーネント | 責務 |
|---|---|
| Visibility Filter | どの情報をモデルに渡し、どれをランタイムだけに留めるかを判断する |
| Authority Resolver | 競合と優先順位を処理する |
| Temperature Manager | Hot / Warm / Cold / Frozen / Long-term Memory を管理する |
| Retrieval Router | ルール、キーワード、ベクトル、ツール、artifact、memory、グラフのいずれから召回するかを決定する |
| Compression Engine | 外部化、抽出、要約、構造化、および rehydrate を担当する |
| Boundary Controller | thread、task、subagent、tenant、permission、sandbox の境界を管理する |
| Context Budgeter | トークン予算、選択の説明、ContextPlan を担当する |
こうすることで、Context Manager は「毎ターン prompt を組み立てるだけのコード」ではなく、デバッグ可能なワーキングセットプランナーになる。
まずは最小限のクローズドループで十分だ。
1. すべてのメッセージとツール実行結果を transcript に格納し、完全に保存する。
2. 毎ターン、モデルリクエストの前に transcript / state / memory / tools から候補コンテキストを収集する。
3. 候補コンテキストにタグを付与する:来源、種類、温度、権威性、トークン見積もり、可視性の有無。
4. 現在のタスクに基づき、最も関連性の高い一批を選択する。
5. サイズの大きいツール実行結果は切り詰めまたは要約する。
6. 直近 N ターンの生メッセージを保持する。
7. 古い履歴はタスク引き継ぎ用の要約に圧縮する。
8. 圧縮要約には、目標・制約・実施済み・失敗・次のステップを強制的に保持する。
9. 圧縮前のすべての元コンテンツは transcript に残し、復元と監査を可能にする。ごく簡素なデータ構造は次のような形になる。
type ContextItem = {
id: string
kind: "instruction" | "user_goal" | "tool_result" | "file" | "summary" | "memory" | "state"
source: string
visibility: "llm_visible" | "runtime_only" | "artifact_ref"
authority: "system" | "org" | "project" | "user" | "task_state" | "retrieval" | "memory" | "summary"
temperature: "hot" | "warm" | "cold" | "frozen" | "long_term"
shape: "raw" | "extract" | "summary" | "reference" | "diff" | "structured" | "graph"
boundary: "thread" | "task" | "subagent" | "tool" | "tenant" | "sandbox"
tokenEstimate: number
freshnessTs?: string
conflictKey?: string
confidence?: number
ttl?: string
content?: string
ref?: string
}そして毎ターン ContextPlan を生成する:
type ContextPlan = {
selected: ContextItem[]
compressed: Array<{ from: string; to: string; method: "extract" | "summarize" | "distill" | "archive_ref" }>
dropped: Array<{ id: string; reason: string }>
conflicts: Array<{ key: string; winner: string; losers: string[]; reason: string }>
budget: {
total: number
used: number
buckets: Record<string, number>
}
}ContextPlan の価値は、その説明力にある。
エージェントが誤ったとき、単に「モデルの回答が間違っていた」で終わらせず、次のように問い詰めることができる。
このターンで実際に選択されたコンテキストはどれか?
どのルールが除外されたのか?
どのツール結果が圧縮されたのか?
長期記憶はなぜ注入されたのか?
あるユーザー制約がプロンプトに入らなかった理由は何か?ContextPlan がなければ、コンテキストの挙動はブラックボックス的な継ぎ接ぎに過ぎない。これがあって初めて、Context Manager はデバッグ可能なシステムとして振る舞う。
毎ターンの呼び出し前に、Context Manager は次の選択を行う。
候補の収集
-> ランタイム限定アイテムの除去
-> 権限の競合解決
-> 失効したツール結果の破棄
-> ホットコンテキストの優先
-> 大きいアイテムの圧縮
-> 直近の末尾の保持
-> 最終コンテキストの注入疑似コードで表すと次のようになる。
function buildContext(task, state, transcript, memory, budget) {
const candidates = collect(task, state, transcript, memory)
const visible = applyVisibilityFilter(candidates)
const resolved = resolveAuthorityConflicts(visible)
const fresh = updateTemperatureAndFreshness(resolved, state)
const retrieved = routeRetrievalIfNeeded(fresh, task)
const shaped = transformShape(retrieved)
const compressed = compressToBudget(shaped, budget)
const selected = enforceBoundaries(compressed, task)
return [
stableInstructions(selected),
projectRules(selected),
taskSummary(selected),
recentTail(transcript),
toolResults(selected),
currentUserInput(task),
]
}ここで最も重要なのはコードではなく、思想だ。
コンテキストは構築されるべきものであり、自然増殖させるものではない。
自然増殖させたチャット履歴は、長く走らせれば必ず汚れていく。
予算も総トークン数だけで見てはいけない。より安定させるなら、バケット単位で割り当てる方法がある。
| 予算バケット | 推奨割合 |
|---|---|
| システム / ポリシー / プロジェクトルール | 10%〜20% |
| 現在のユーザー入力 + タスク状態 | 10%〜20% |
| 直近の末尾(Recent Tail) | 15%〜25% |
| 検索により取得したコンテキスト | 20%〜35% |
| ツール実行結果 / アーティファクトプレビュー | 10%〜20% |
| 長期記憶 | 5%〜10% |
予算超過時、第一手として直近の会話を削るのは避けるべきだ。
より合理的な順序は、通常次のようになる。
まず信頼度の低い検索結果を削除
-> 次に期限切れのメモリを削除
-> 大きなツール実行結果をアーティファクト参照に置き換え
-> 古い履歴を圧縮
-> 最後に直近の末尾(recent tail)を短縮直近の末尾は現在の文脈感覚を担っていることが多く、早々に削るとモデルが突然「遠く」なってしまう。
MVP は以下のロードマップで進めるとよい。
| バージョン | 目標 |
|---|---|
| v0.1 | 直近 N ラウンド、タスク状態 JSON、プロジェクトルール、アーティファクト外部化、手動コンパクト、ContextPlan ログ |
| v1.1 | キーワード / ベクトル / ハイブリッド検索と鮮度フィルタの追加 |
| v1.2 | メモリ名前空間、TTL、競合解決の追加 |
| v1.3 | サブエージェントコンテキスト、構造化レポート、親マージの追加 |
| v1.4 | マルチテナント戦略、権限考慮型検索、監査と説明 UI の追加 |
10. 圧縮サマリーの書き方
多くのシステムで compact が不安定なのは、サマリーの目的を間違えているからです。
「これまでのあらすじ」として扱い、「引き継ぎ資料」として扱っていません。
Agent にとって、より良い compact テンプレートは次のとおりです。
ユーザー目標:
[ユーザーが最初に達成しようとしていたこと]
ハード制約:
[違反してはならないルール、ユーザーの明示的要求、権限の境界]
現在の状態:
[タスクが今どのステップで止まっているか、漠然とした要約ではないこと]
確認済みの事実:
[ファイル、ログ、ツール結果から確認された事実、出典付き]
既読ファイル:
[ファイルパス + 読み取った要点 + 期限切れの可能性の有無]
変更済みファイル:
[ファイルパス + 変更内容 + 変更理由]
試行して失敗した手段:
[次のラウンドで同じ失敗を繰り返さないために]
直近の検証結果:
[コマンド、結果、失敗メッセージまたは通過の証拠]
次の一手:
[圧縮後に最初に続行すべきこと]このテンプレートの要点は「続行可能であること」です。
履歴を知っているだけでは意味がありません。Agent は次にどこから再開すべきかを把握していなければなりません。
11. 選定時に問うべき質問
独自のエージェントシステムを設計するなら、「どのフレームワークが最強か」から入ってはいけない。
まずは次の質問を自問しよう。
自分のエージェントは低レイテンシの補完か、長時間のタスク実行か?
タスクの状態は構造化できるか?
ツールの実行結果は非常に長くなり得るか?
セッションを跨いだ記憶が必要か?
マルチエージェントの協調が必要か?
エンタープライズレベルの権限管理や監査が必要か?
モデルに内部のランタイム状態を参照させることを許容するか?
失敗時にリカバリが必要か?
コンテキスト圧縮時に最も失いたくないものは何か?答えによって導かれる設計は変わる。
- IDE 補完なら、局所コードコンテキストと低レイテンシなインデックスを優先する。
- ワークフロータスクなら、State・チェックポイント・リカバリ可能な実行を優先する。
- アプリケーション SDK なら、ローカルコンテキストと LLM コンテキストの分離を優先する。
- プログラミング CLI エージェントなら、ツール結果の統制・圧縮・直近末尾の管理を優先する。
- マルチエージェントなら、境界・役割・ハンドオフ・構造化成果物の設計を優先する。
- 長期的なパーソナルアシスタントなら、記憶の階層化・スキルの蓄積・有効期限戦略を優先する。
- エンタープライズフローなら、権限・承認・シークレット・監査をコンテキスト体系に組み込むことを優先する。
これは「どのモデルが強いか」を直接比較するより、はるかにエンジニアリングの現実に即している。
12. 一言まとめ
この章を一言に圧縮すると:
Context Manage とは、より多くのコンテンツをモデルに詰め込むことではない。限られたウィンドウの中で、「どの情報をモデルに見せるべきか」「どのような形で見せるか」「いつ見せるか」「期限切れ後にどう処理するか」「容量不足のときにどう圧縮するか」「タスク中断後にどう復元するか」を継続的に判断することである。
さらに六つの単語に圧縮すると:
選択(Selection)
注入(Injection)
呼び戻し(Recall)
圧縮(Compaction)
隔離(Isolation)
復元(Recovery)Claude Code、LangGraph、OpenAI Agents SDK、AutoGen、Cursor、Hermes、OpenClaw —— これらのプロジェクトは一見まったく異なるように見えるが、いずれも同じ根本的な問いに答えようとしている:
モデルに真の記憶がなく、
それでもタスクを連続的に前に進めなければならないとき、
外部システムはモデルが「そのターンに見るべき世界」をどのように管理するのか。これこそが Context Manage の価値である。
Context Manage は Agent の付属機能ではなく、Agent Harness の中核的能力の一つなのだ。